From framework to live product
in 40 hours.
The Problem
Most professionals know AI matters. Almost none of them can tell you where they actually stand.
The existing options are not helpful. On one end, ten-question quizzes that tell you nothing. On the other, academic instruments designed for researchers, not business leaders. Nothing in between measures practical AI proficiency in business terms and points you toward what to learn next.
I needed an assessment that sorted people into a clear framework, gave them an identity they wanted to share, and pointed them toward a next step. It did not exist. So I built it.
The Decision
The 7 Levels of AI Proficiency framework already existed. It is the foundation of every LaunchReady program, developed and refined over years of training delivery, and it sits at the center of the book. Frameworks only matter if people can place themselves in one.
I decided to build a full adaptive assessment on top of it. Scenario-based questions, weighted scoring, and a progression model that stops when it finds your ceiling.
The goal: someone takes the assessment, gets a result that feels accurate, sees a badge worth sharing, and lands in my email system tagged by level. One product doing lead generation, audience segmentation, and brand building at the same time.
Level 5 · Captain (Design Thinker)This case study references the 7 Levels of AI Proficiency, the framework developed by LaunchReady.ai that maps how professionals progress from basic AI use to full orchestration. Inline tags throughout show which level a specific decision represents. Take the free assessment at assess.launchready.ai to find your own level.
What I Built
Two production sites in 10 days.
assess.launchready.ai · the proficiency assessment
- Adaptive 7-level model. Five questions per level. Stops at your ceiling.
- 35+ scenario questions with Guttman and partial-credit scoring, calculated server-side.
- Seven photoreal challenge coin badges, one per level.
- Dynamic OG share cards (1200x630 PNG) generated per result.
- LinkedIn share copy engineered around a recognizable pattern.
- Supabase database with migrations and session tracking.
- Rate-limited API, Turnstile CAPTCHA, localStorage resume.
- Kit integration that auto-tags every subscriber by their level.
- Email drip sequences calibrated to each result.
launchready.ai · full marketing rebuild
- Programs, coaches, testimonials, pricing.
- Assessment integrated across every surface.
- Full SEO: meta tags, OG, JSON-LD, canonical URLs, sitemap, robots.txt.
- GA4 event tracking end to end.
How It Happened
| Day | What shipped |
|---|---|
| Mar 7 | LaunchReady.ai v2. Marketing site, program cards, coach bios, pricing. |
| Mar 8 | Polish. Name fixes, layout tweaks. |
| Mar 10 | Assessment v1. Next.js scaffold, Supabase schema, results page, Turnstile, rate limiting. |
| Mar 11 | Email gate, Kit integration, brand pass, redesign, drip sequences. |
| Mar 12 | OG share images, trajectory map, badge renders, scoring fixes, SEO. |
| Mar 13 | localStorage persistence, audit cleanup. |
| Mar 16 | Adaptive 7-level system, challenge coins, results page overhaul, LinkedIn share copy, home page rewrite. |
V2 was built on top of V1's infrastructure in about three to four hours. Same database. Same email pipeline. Same deployment. That is the compound effect of building systems, not just features.
Level 6 · Admiral (Systems Integrator)What 40 Hours Actually Looks Like
People hear "AI built it" and assume I typed a prompt and walked away. Here is the actual breakdown.
Question authoring and scoring calibration (~10 hours)
Translating the 7 Levels framework into 35+ real business scenarios. Building the Guttman and partial-credit scoring model. Calibrating difficulty so each level actually discriminates against the one above and below it. AI drafted questions. I evaluated every single one against the framework, rewrote weak items, adjusted answer weights, and killed anything that felt like a quiz instead of a real assessment. The framework was the input, not the output.
Level 5 · Captain (Design Thinker)Product design and UX (~8 hours)
How should the flow feel? When do you show results? Where does sharing sit? What creates the emotional high that drives virality? These decisions came from studying what makes MBTI, CliftonStrengths, and Spotify Wrapped spread. I mapped the emotional arc of the experience before writing a line of code.
Visual design and brand (~6 hours)
Seven challenge coin designs that feel earned, not given. OG share cards optimized for the LinkedIn feed. Brand consistency across two sites. Circular coins are native to profile frames. Dark metallic on navy pops against a white feed. None of this is random.
Content and copy (~5 hours)
Landing page copy. Results page personalization for each of the 7 levels. LinkedIn share text built around a recognizable "there are 7 levels" opener. Email drip sequences. Writing for conversion while sounding like one real person talking to another.
Technical architecture and iteration (~6 hours)
Schema decisions. API design. Email integration. Security including rate limiting, Turnstile, and server-side scoring. Debugging edge cases. The technical work was real, but it moved fast because I was making architecture decisions while Claude wrote the implementation.
Quality and competitive analysis (~5 hours)
I benchmarked every surface against 16Personalities, CliftonStrengths, and Spotify Wrapped. Scored the landing page, results page, and OG share card on structured rubrics. Found gaps. Closed them. Final scores: landing 78/100, results 80/100, OG card 82/100. The biggest remaining gap is social proof, which grows as the taker count grows.
Level 3 · Lieutenant (Critical Thinker)What This Would Cost Traditionally
| Approach | Estimated cost | Timeline |
|---|---|---|
| Freelance team (5 to 6 specialists) | $10,000 to $25,000 | 3 to 4 months |
| US agency | $15,000 to $35,000 | 4 to 6 months |
| Harrison + Claude Code | ~$133 per month + 40 hours | 10 days |
The freelance estimate covers an I/O psychologist for the assessment design, a frontend developer for two sites, a graphic designer for coins and share cards, a copywriter, and an SEO specialist. The agency estimate adds project management and margin. Both are based on 2025-2026 rate data from Salary.com, Clutch.co, and industry benchmarks.
The Decisions That Shaped It
Adaptive over fixed
V1 had 27 fixed questions. Everyone answered everything. V2 adapts. Five questions per level. Stops when you hit your ceiling. It respects the user's time and produces a more accurate result. "What level did you get?" is a better conversation than "what was your score?"
Challenge coins over generic badges
Military challenge coins feel earned. They are circular, which is native to LinkedIn profile frames and social feeds. They have a collectibility factor. Dark metallic on navy pops in a white feed. Generic badges feel like participation trophies.
Level 5 · Captain (Design Thinker)Share section in position two
Most assessment sites bury sharing at the bottom. The emotional high is right after seeing your result. That is when people share. I put the share section immediately after the hero badge, before strengths, before next steps, before anything else.
Strengths spotlight over radar chart
Radar charts look analytical. They do not drive sharing. Research on viral assessments shows identity reinforcement drives sharing far more than data visualization. Strengths do that work. Charts do not.
"There are 7 levels" opening line
Every LinkedIn share opens with the same line. When multiple people share, it creates a recognizable pattern in feeds. Same mechanic that made "I am a [type]" go viral for MBTI.
Level 6 · Admiral (Systems Integrator)Segmentation baked into the product
Email tagging by level means every person who takes the assessment enters my system pre-segmented. Level 2 people get different content than Level 5 people. The assessment is not just a product. It is a segmentation engine.
What This Means for You
This is not a story about AI replacing professionals. An I/O psychologist with 20 years of experience would build a better assessment than mine. A senior developer would write cleaner code. A brand designer would produce more polished visuals.
I did not need perfect. I needed real. A working product, live in the world, collecting users and building my email list while I figure out what to improve.
The 40 hours were spent thinking. Designing. Evaluating. Deciding what to build, how it should feel, and what "good enough to ship" actually looks like. AI handled the implementation. I handled the judgment.
Direction, not prompting.
Judgment, not output.
Frequently Asked
What is the 7 Levels AI proficiency assessment?
An adaptive 35+ question assessment built on the 7 Levels of AI Proficiency framework. Scenario-based questions with weighted scoring, a progression model that stops when it finds your ceiling, and a challenge coin badge at your result level. Free to take at assess.launchready.ai.
How long does it take to build an assessment product like this?
Harrison built two production sites (the assessment plus the full LaunchReady.ai rebuild) in 40 hours across 10 days. Traditional builds run 3 to 6 months using a freelance team or an agency.
Can you build a psychometric assessment with AI?
Yes, with a human directing the design. AI drafted questions and wrote the code. A human brought the existing 7 Levels framework, calibrated the scoring model against it, evaluated every scenario against the levels, rewrote weak items, and benchmarked the experience against MBTI, CliftonStrengths, and Spotify Wrapped. The judgment is the product.
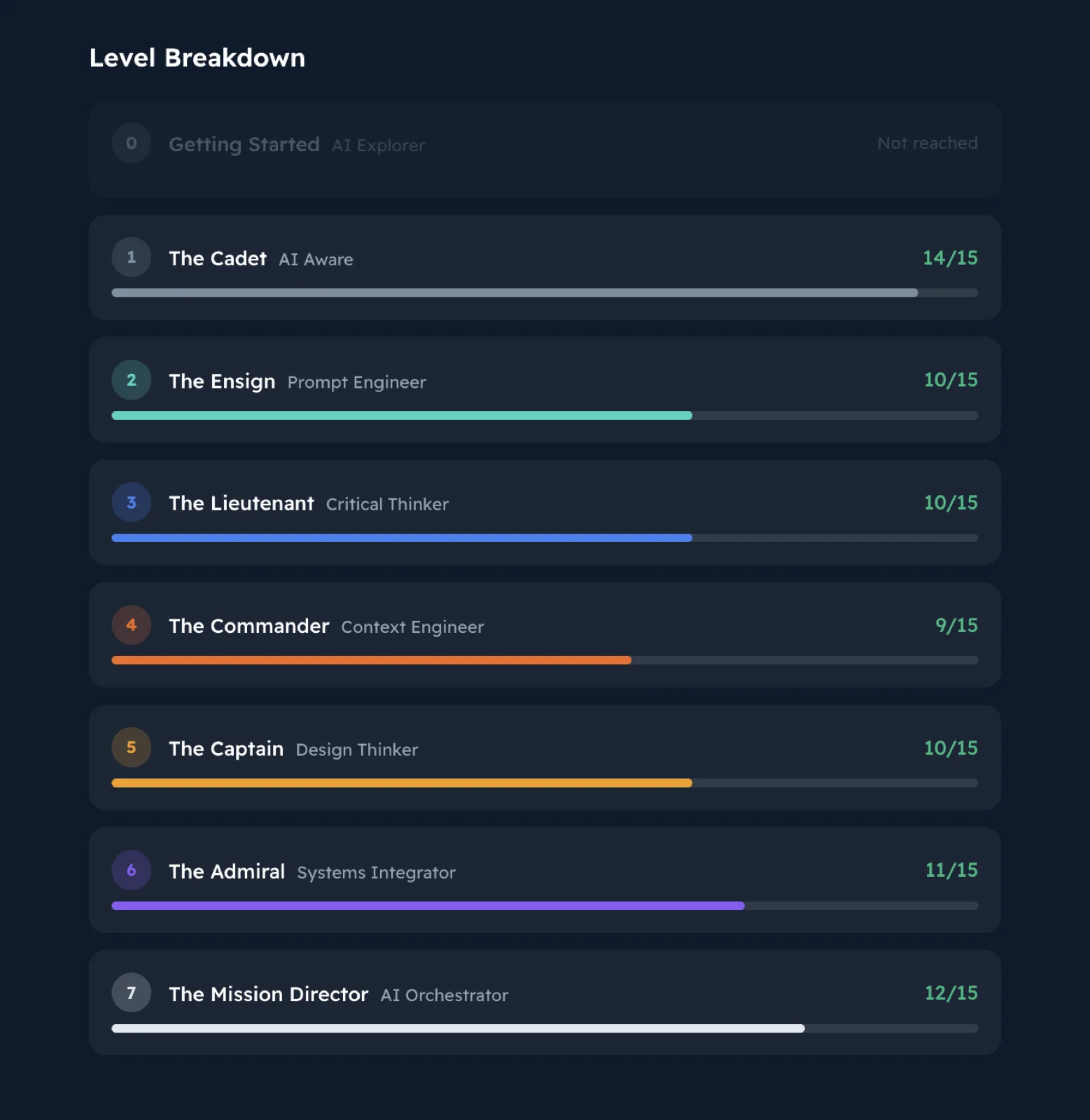
The 7 Levels of AI Proficiency
A measurable ladder from where your team is today to where the work needs them to be. Each level is defined by a human skill, not a technical one.

Ready to find your level?
Take the free assessment, or book a discovery call to talk about the 7 Levels Engagement.